Multi-AZにおけるEC2インスタンスのアクティブ・スタンバイ制御
あんまし技術的な記事を書いてなかったから、久しぶりに書くよ。
内容は表題の通り。大まかな制御フローとしては
・あるAZ内に配置したインスタンスAの状態を取得(これをA-statusと呼ぶ)
・A-statusが"running"なら、他方のAZに配置したインスタンスBを停止する(停止中なら何もしない)
・A-statusが"running"以外なら、他方のAZに配置したインスタンスBを起動する
というもの。あんまし難しくはないと思ってる
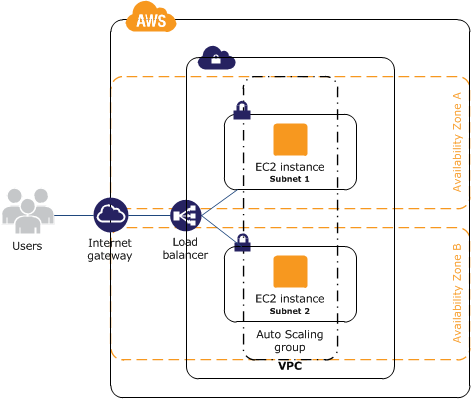
AWS環境構成
以下の写真の通り、複数AZにEC2インスタンスを配置し、ELBを使ってリクエストを振り分けるよ。
この構成自体はよくやるやつだと思うので、全然珍しくはないよね
しかしながら
ただ問題なのは、この構成のままだと、以下のどれかの方法でEC2のMulti-AZを実現するくらいしか思いつかない点である。
1. 常に両AZ内のインスタンスを稼働させ続ける
2. 最初に片方AZのインスタンスを稼働させ、もう片方AZのを停止させておく。片方AZの異常でインスタンスが使えなくなったら、手動でもう片方AZのを起動する
方法1.は常に稼働させ続けるので、料金がかかるのが懸念点。そもそも「Multi-AZ」とは、個人的解釈で言うと
「片方のAZに異常が起きて正常利用できない時に、もう片方の正常なAZに切り替えることでサービスの提供を維持できるようにする」
というもので、逆に言えば「片方のAZが正常利用できるなら、もう片方は稼働させ続ける必要はない」のである。
少なくとも稼働時間に応じて料金がかかってしまうEC2インスタンスにおいては、不要ならば停止させておきたいと考えるのは自然なことだと思われる。
方法2.の方は、料金はかからないが、手動で行う都合上、復旧までにタイムラグが起きてしまう点が懸念点。
昼間仕事中に異常を検知してすぐに切り替えることができれば何も問題はないが、
夜中寝てる時や昼間でも早急に対応ができない時は、対応するその時まで異常状態が続いてしまう。
当然その間はサービスを提供することができないので、お客さん激おこ案件である。それだけは何としても避けたい。
CloudWatchで監視でいいんじゃね?
色々ググると、CloudWatchで監視して、異常検知したらEC2を起動するようにイベントを仕込むって方法があるっぽい????んだけど、
何やらごちゃごちゃ設定しなくちゃいけなくて、設定項目も何やらいっぱいあって正直よくわからない。できるんだろうけども、個人的にはあんま気乗りしなかった。
自分で書いちゃえ
よくわからなくなるくらいなら、自分で制御スクリプト(shellscript)を書いちゃえってことにしました。
自分で書く分制御の仕組みを把握できるので、安心できるのがいいよね。まあ、これは人によるだろうけれども。。。
というわけで、スクリプトを作るわけだけれども、その前にまずは、監視用のサーバーを別途立てる必要があります。そして監視用サーバー自体は
インスタンスA,Bを配置したAZではない、全く別のAZに配置するべきでしょう。じゃないとMulti-AZの監視をする意味がないので。
リージョンまで別にする方が安全面ではよりベターなんだろうけれども、別のリージョンからアクセスするための設定がこれまたゴチャゴチャめんどいので、
今回は同一リージョン内の別AZというやり方でいきます。
さあスクリプトを!、と思うのだけど、まだ準備が必要です。監視用サーバーにて、
1.aws-cliをセットアップ
2.jqコマンドを使えるようにする
という作業があります。
インスタンスを操作するので、aws-cliは必須です。aws configureでちゃちゃっとセットアップしましょう。
2つめのjqコマンドですが、aws-cliを実行して返却されたjsonを読み取るために必要になります。そもそもjqコマンドは、
シェル上でjsonを簡単に扱えるようにするためのコマンドで、デフォルトではインスタンスに入っていないものです。みんなだいすきyumコマンドで
インストールができるので、いれちゃいましょう。
$ sudo yum install -y jq
スクリプト書いてみたよ
というわけで、ここまで準備できてようやくスクリプトを書くよ!
出来上がったものがこちらですよ!
#!/bin/bash echo "Start operation" MAIN_AZ_INSTANCE_ID="i-XXXXXXXXXXXXXXXX" SUB_AZ_INSTANCE_ID="i-XXXXXXXXXXXXXXX" MAIN_INSTANCE_STATUS=$(aws ec2 describe-instance-status --instance-id ${MAIN_AZ_INSTANCE_ID} | jq '.InstanceStatuses[0].InstanceState.Name') SUB_INSTANCE_STATUS=$(aws ec2 describe-instance-status --instance-id ${SUB_AZ_INSTANCE_ID} | jq '.InstanceStatuses[0].InstanceState.Name') echo "Current MAIN_INSTANCE_STATUS" echo ${MAIN_INSTANCE_STATUS} echo "Current SUB_INSTANCE_STATUS" echo ${SUB_INSTANCE_STATUS} if [ ${MAIN_INSTANCE_STATUS} != "\"running\"" ]; then echo "START sub" # START SUB INSTANCE SUB_INSTANCE_STATUS_AFTER=$(aws ec2 start-instances --instance-ids ${SUB_AZ_INSTANCE_ID} | jq '.StartingInstances[0].CurrentState.Name') echo "After SUB_INSTANCE_STATUS" echo ${SUB_INSTANCE_STATUS_AFTER} else echo "STOP sub" # STOP SUB INSTANCE SUB_INSTANCE_STATUS_AFTER=$(aws ec2 stop-instances --instance-ids ${SUB_AZ_INSTANCE_ID} | jq '.StoppingInstances[0].CurrentState.Name') echo "After SUB_INSTANCE_STATUS" echo ${SUB_INSTANCE_STATUS_AFTER} fi echo "Finish operation"
記事の一番最初に書いた大まかな制御フローをそのままスクリプトに落とし込んだだけ。
スクリプトでは起動後/停止後の状態をechoして、ちゃんと起動したか/停止したかを出力してます。ec2コンソールからでも状態は確認できるから、
不要かもね。
ひとつだけ注意なのは、今回は1インスタンスずつしか配置していないことです。本来はもっとたくさんインスタンスができると想定されるので、
状態チェックや起動/停止はfor文回して複数回行われると考えて差し支えないかと
cronに監視してもらおう
スクリプトできた!ばんざい!任務完了!
といきたいところだが、戦いはまだ終わっていない。あくまでスクリプトができただけで、こいつを実行するための仕組みがまだ整っていないのだから!
まあ、そうはいってもcronをしこんでおしまーい、くらいなもんなので、ここまできたらもう難しくはない認識だよ。
肝となるのは実行するタイミングをいつにするか、なんだけど、異常発生時から復旧までのタイムラグを極力無くしたいという観点から、
10分に1回の頻度くらいでちょうどいい気がしますね。ただ、監視するインスタンスの数が多いと、その分状態チェックや起動/停止に時間がかかるだろうから、
その辺は環境とよく相談が必要かもしれませんね